人工智慧再进化! AI也能做智力测验了? !
2018.07.24
"2016年AlphaGo成功打败围棋好手李世石的新闻大家是否还记得呢?如今2年多的时间过去了,AlphaGo也历经了不断的进步和被AlphaGo Zero超越的种种事件。 AlphaGo的成功归功于他的开发团队DeepMind的不断训练与改良,现在DeepMind团队更已经开始着手训练AlphaGo利用抽象思考来模拟人类的演算推理,期望未来人工智慧不再只是局限于一问一答、深度学习等等的框架,而能够越来越趋近于人类的思考模式,让我们一起来看看DeepMind团队的计画吧~"
AlphaGo開發團隊DeepMind已經開始訓練人工智慧何謂「抽象思考」,希望未來人工智慧能像真正的人類一樣藉由推演思考回答問題。[引用來源]
在藉由游戏等方式训练人工智慧系统之后,DeepMind团队接下来也计画让人工智慧挑战智力测验。
根据《新科学人》杂志报导,位于英国伦敦的Google DeepMind团队计画藉由智力测验方式训练人工智慧,借此让人工智慧能有更具抽象「思考」能力。
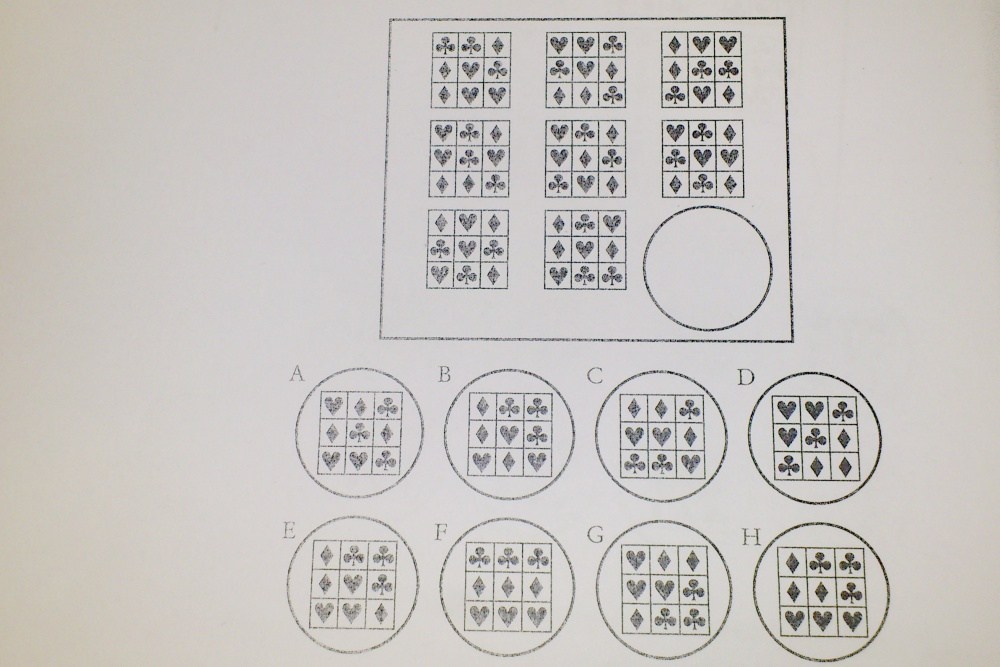
而DeepMind团队所采用训练方式,则是透过1936年由英国心理学家John Raven提出的瑞文氏图形智力测验(Raven』s Progressive Matrices),藉由渐进矩阵构图组成题组,以有复杂难度层次变化方式,判断人工智慧从「直接观察(比对)」到「抽象推理」过程所表现「智力」。
由于瑞文氏图形智力测验并非仅以单纯比对,更包含以抽象思考推理方式解题,甚至后来还针对儿童加入色彩推理,并且针对高智商者提出瑞文既皆推理测验(Raven』s Advance Progress Matrice),甚至后续更将测试内容整合提出可对应5岁至75岁年龄间智力量测版本,成为在全球广泛被用于测试智力的项目之一。
就DeepMind团队说明,透过智力测验方式训练人工智慧,并非为了打造可顺利解答智力测验的人工智慧系统,而是希望能让人工智慧能更接近人脑思考模式,能以现有资讯判断决策之余,更能藉由逻辑推演、抽象思考方式寻求解答,甚至能像人脑一样透过反射思考模式进行判断。
Follow 我们的Page,每天追踪科技新闻!
想看更多英文版文章吗? 点我进去~